Lightspeed Memory is nVidia's answer to
a memory bandwidth problem they've been having. It's no secret that the
GeForce 2, while being a very fast chip was severely limited by slow memory.
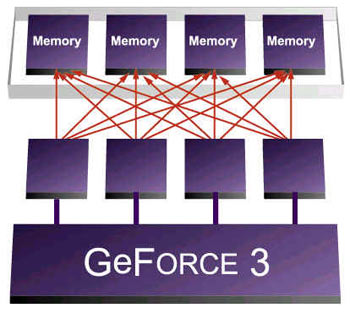
The first part of the LightSpeed Architecture is the Crossbar Memory Controller.
This is a very basic overview on what it is. Since older GeForce based cards
have a 256 bit (128 bit DDR) based memory subsystem, let's say an object
being rendered is 128 bits in size, it would be a big waste of bandwidth
to only use 128 bits of that 256 bit (128 bit DDR) controller. We'd only
be utilizing 50% of the available bandwidth, thus wasting the other 50%.
With the new Crossbar Memory Controller, the total available 256 bit data
pathway has been broken down to 4 64-bit "chunks" and in this
case if we were only using 128 bits of the available 256 only 128 bits of
data would be sent to the GPU. Crossbar technology allows for much more
efficient data transfers.
Z-Occlusion Culling
The next thing special thing about LightSpeed Memory is that
it implements a special form of compression on the Z level called "Lossless
Z Compression". This is a form of hardware compression/decompression that
takes place in the memory sub system and can compress the data sent to it by
a multiple of 4, thus freeing up even more memory bandwidth with no loss of
picture quality! The next big thing integrated into LightSpeed is
Z-Occlusion Culling.
What's that you ask? Simple, what you see is all that is
rendered. What Z-Occlusion Culling does is the GPU try's to "see" what is
going to be rendered in a given scene and what won't. If it's determined
that an object is not going to be seen, it's not going to be rendered.
LightSpeed Memory is much more efficient then older memory subsystems. It
could be said that nVidia was emulating ATI, since this technology is
quite similar to ATI's HyperZ.
